Programming an FPGA
{kind=link}
Anatomy of a Module
When you create any design, you will have a top-level module. This is the module whose inputs and outputs are actual inputs and outputs on the FPGA’s pins. For any Alchitry project, these are either cu_top.luc or au_top.luc depending on the board (Cu or Au) you are using.
The initial top-level modules for either board look essentially identical.
module au_top (
input clk, // 100MHz clock
input rst_n, // reset button (active low)
output led [8], // 8 user controllable LEDs
input usb_rx, // USB->Serial input
output usb_tx // USB->Serial output
) {
sig rst; // reset signal
.clk(clk) {
// The reset conditioner is used to synchronize the reset signal to the FPGA
// clock. This ensures the entire FPGA comes out of reset at the same time.
reset_conditioner reset_cond;
}
always {
reset_cond.in = ~rst_n; // input raw inverted reset signal
rst = reset_cond.out; // conditioned reset
led = 8h00; // turn LEDs off
usb_tx = usb_rx; // echo the serial data
}
}
Port Declarations
The first section of the module is the port declaration. This is where you declare the inputs and outputs to your module.
In this case, since it is the top-level module, these are signals on the board itself.
input clk, // 100MHz clock
input rst_n, // reset button (active low)
output led [8], // 8 user controllable LEDs
input usb_rx, // USB->Serial input
output usb_tx // USB->Serial output
You may have noticed the led input has a number in square brackets after it. This makes it not one, but eight individual inputs bound together as an array. We will get more into array syntax later.
A module may also have a list of parameters that can be used to customize the module. This list is omitted here and would be pointless on a top-level module since the parameters are passed in by the parent module instantiating it. The term instantiation is used to refer to when a module or other resource is added to your design. It means that an instance of that module or other resource is created.
When you write code, each time you call a function the exact same instructions are used over and over again no matter how many times the function is called. However, every time you instantiate a module, the entire circuit that composes the module is duplicated. If you want to reuse the same resources for multiple tasks, it is your job as the designer to figure out how you are going to juggle that.
Speaking of instantiation, typically you instantiate everything your module needs right after the port declaration.
The first line is declaring a signal using the sig keyword.
sig rst; // reset signal
Signals aren’t memory. They don’t store any values. You should think of them as wires. A wire can have a value, but it is really just a connection from one point to another.
In this design, we are using the signal rst as a placeholder for the output of the reset_conditioner module. Instantiating this module is what the next couple of lines do.
.clk(clk) {
// The reset conditioner is used to synchronize the reset signal to the FPGA
// clock. This ensures the entire FPGA comes out of reset at the same time.
reset_conditioner reset_cond;
}
To instantiate anything, you simply use the name of the resource followed by the name of this particular instance. So the line reset_conditioner reset_cond; creates an instance of the reset_conditioner module named reset_cond. The block that this instantiation is wrapped in is called a connection block. This block allows you to connect an input or parameter with a given name of many modules to the same signal.
In our case, we are connecting the input clk to the signal clk (which is an input to our module). The syntax is .port(signal) where port is the name of the input on the module being instantiated and signal is the signal to connect to it.
The reset_conditioner module has an input named clk so this input is directly connected to the signal clk in our module.
You could also connect this directly to the module on the line of instantiation like this:
reset_conditioner reset_cond(.clk(clk));
This wasn’t done here because the input clk is part of almost any module and it is convenient to have a block like this setup so you can simply add your other instantions that need to be connected to clk.
Almost every module will have a clk input and often they will have a rst input for a reset. Exactly what a clock and reset are used for will be covered later.
You can add multiple connections to the same connection block like this:
.clk(clk), .rst(rst) { … }
You can also nest the blocks and since not every block that uses clk uses rst - usually you will see something of the following form in the beginning of a module.
.clk(clk) {
// clk only instantiations
.rst(rst) {
// rst and clk instantiations
}
}
Always Blocks
The next section is the always block. This is the meat of the module.
Always blocks are where you describe all the logic that happens in your module. They contain something known as combinational logic. Combinational logic is any digital circuit whose output is a function solely of the current inputs. They have no internal state or memory. A good example of this is an addition circuit. The output is solely determined by the two numbers currently being input. It doesn’t matter what the last numbers input were or how many times you changed the numbers. The output is always a function of the current inputs.
Inside the always block we write statements. The statements are composed of four main types. Assignments, if statements, case statements, and for loops.
Assignments
Assignments are by far the most common. You have some signal on the left followed by an equals sign and then an expression.
signal = expression;
The power of these comes from the expression. Here you can use a handful of different operators to manipulate bits. These include some mathematical operators like +, -, and *. Notably, / for division can not be used if the expression is dynamic. This is because division is too complicated for the tools to have a reasonable default to drop in for you. Division is still possible, it just requires a bit more effort and planning.
If Statements
If statements follow your typical layout:
if (expr) { … } else { … }
If the expression following the if is true (non-zero) then the first set of lines are valid. If it is false (zero) the lines in the else block are valid. The else portion is optional.
Notice I said valid and not executed. It can be easy to fall into the trap when you have if statements and for loops to get in the programming mindset.
If statements are most often realized in hardware with a multiplexer. You are simply selecting one of two inputs based on some expression.
When you assign a signal a value in an always block, no matter what the conditions are, it must be assigned a value. This usually means that if you assign a value to something in an if statement you should have a matching assignment in the else portion of the statement.
The one exception to this rule is the d input of a dff or fsm type. These are covered later.
Another way to ensure you always assign a value is to begin your always block with some reasonable default values. Take a look at the following pseudo-code:
led = 0;
if (button_pressed)
led = 1;
When the button isn’t pressed, the led has the value 0. However, what happens when the button is pressed? Does led get assigned a value of 0 then updated with a value of 1? Nope.
When the button is pressed, led always has a value of 1. Assignments lower in an always block take precedence over previous assignments.
You can think of the block being evaluated always and instantaneously.
Now, imagine we didn’t have that default value before the if statement. What value would led have when the button isn’t pressed? It is tempting to assume that it would just keep its previous value but remember signals can’t store values. They are simply like wires connecting two things together.
With the default value of 0, we could realize this in hardware with a multiplexer.
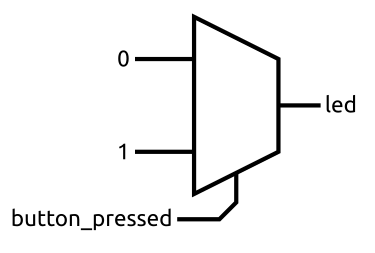
In this trivial case, it could be simplified by just connecting the led and button_pressed signals together.
Case Statements
Case statements follow the following syntax:
case(expr) {
value: statement;
value: statement;
default: statement;
}
These work exactly the same as if statements but are just a simpler way to have many branches on a single expression. The value part of the case statement needs to be some constant. The optional default branch is a catch all.
Unlike with code, case statements don’t offer any performance improvements over many if statements. They are solely for code clarity and convenience.
For Loops
Finally we get to for loops. For loops in Lucid share the syntax to C or Java for loops but have some restrictions:
for (init; eval; increment) { … }
They are usually used with a var type which is used to store values that won’t directly show up in the circuit but are used in the description.
The big restriction on for loops in hardware is that they must have a constant number of iterations.
This is because the tools need to be able to unroll the loop. A for loop is no different than copy pasting that section of code over and over again except it is much easier to read. You should typically avoid them unless you have a good reason to use one. It is very easy to create a very large and slow circuit using for loops.
Numbers
In Lucid, there are a handful of ways to define a numeric constant. The easiest way is to simply type the number like 14.
When you see a lone number, it is in decimal (radix of 10) and the number of bits used to represent it are the minimum required in an unsigned format, unless it is negative.
If you want more control over the number of bits used, you can prefix the number with xd where x is the number of bits to be used. For example, 8d14 is the decimal value 14 represented with 8 bits.
You can trade out the d for h to use hexadecimal (radix of 16), or b for binary (radix of 2). With both of these formats you can specify the number of bits to use before the letter.
If you omit the number of bits, hexadecimal numbers default to using 4 bits per digit. For example, h08 uses 8 bits since I wrote two digits even though the value 8 could be represented with only 4 bits.
For binary, the number of bits is simply the number of digits when not explicitly specified. So, b101001 is six bits wide.
If a decimal number is written with the d but the number of bits omitted, it behaves the same as if the d was omitted as well.
Arrays
Many signals you will encounter will be multi-bit signals like the led input in our top-level module.
Bits in an array can be individually indexed using the syntax signal[bit] where bit is some expression. It is your job to ensure that the value will always fall within the bounds of the array if it is a dynamic value.
You can also access subsets of the bits using the array syntax [max:min]. Here the range of bits starting at min and going to max, inclusive, are selected. When using this syntax, both values need to be constants.
If you want to dynamically select a subset of bits you can use the syntax [start+:width]. Here start is the lowest bit to be selected and width is the number of bits to select above it (including the start bit). With this syntax, only width needs to be constant. You can also use the slight variation [start-:width]. With this syntax, start is the highest bit in the selection instead of the lowest.
Arrays in Lucid can be multi-dimensional. When declaring them you simply tack on some extra dimensions like this:
sig my_array[dim1][dim2][dim3];
All dimensions of an array must be declared with constant values.
You can then index the array using the selectors as before. Note that you can only use the sub-array selections as the last selector though.